

Il existe énormément d’outils et de frameworks Big Data dans le marché et il est très facile de se perdre car les technologies avancent vite. Cependant, comprendre que l’écosystème Big Data peut être grouper en différentes classes de technologies qui ont des fonctionnalités similaires.
Dans cet article, nous allons voir les différents groupes de technologies et outils. Commençons par les Système de fichiers distribué
Système de fichiers distribué
HDFS
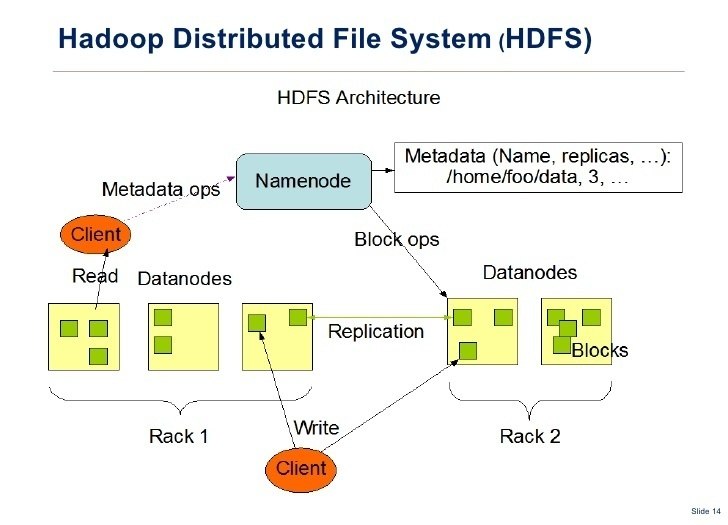
Un Système de fichiers distribué est similaire à un système de fichier normal, sauf qu’il tourne sur plusieurs serveurs en même temps. Cela dit, vous pouvez faire les mêmes manipulations des fichiers que dans un système normal.
Tout système de fichiers permets d’effectuer des actions telles que le stockage, lecture et suppressions des fichiers et permets aussi de sécuriser ces fichiers. L’avantage des Système de fichiers distribué c’est qu’il permets :
- Il peut stocker des fichiers de grandes tailles qu’un ordinateur personnel ne peut pas gérer.
- Les fichiers sont automatiquement répliqués sur plusieurs serveurs pour des opérations de redondance ou parallèles, tout en masquant la complexité liée à la tâche de l’utilisateur.
- Le système évolue facilement: vous n’êtes plus lié par la mémoire ou le stockage restrictions d’un seul serveur.
Dans le passé, pour faire évoluer son système, il fallait changer le serveur par un serveur plus puissant et par conséquent déplacer les fichiers vers ce nouveau serveur. De nos jours, il suffit d’ajouter un petit serveur.
Ce principe rend le potentiel de mise à l’échelle pratiquement illimité.
Le système de fichiers distribué le plus connu à l’heure actuelle est le système de fichiers Hadoop (HDFS). Il s’agit d’une implémentation open source du système de fichiers Google. Cependant, il existe de nombreux autres systèmes de fichiers distribués: système de fichiers Red Hat Cluster, système de fichiers Ceph et système de fichiers Tachyon, pour n’en nommer que trois.
Framework de programmation distribuée
Une fois que vous avez les données stockées sur le système de fichiers distribué, place au code et a la programmation.
Un aspect important du travail sur un système de fichiers distribué est que vous ne déplacez pas vos données vers votre programme. Mais que vous déplacerez votre programme vers les données. Lorsque vous programmer avec un langage tel que C ou Python, vous devez gérer les complexités de la programmation distribuée. Mais, grâce à la communauté open source de nombreux frameworks pour gérer cela à votre place ont été développés. Ils vous donnent une bien meilleure expérience de travail avec les données distribuées et la résolution de nombreux problèmes qu’elle comporte.
Framework d’intégration des données
Une fois que vous avez mis en place un système de fichiers distribué, vous pouvez ajouter des données ou les déplacer d’une source à une autre. C’est là que les frameworks d’intégration de données tels que Apache Sqoop et Apache Flume sont extrêmement utiles.
Le processus, ici, est similaire à un processus d’extraction, de transformation et de chargement dans un entrepôt de données traditionnel.
Framework de Machine Learning

Sckit-Learn
Lorsque vous avez les données en place, il est temps de les analyser pour en extraire des informations. C’est là qu’on utilise les outils d’apprentissage automatique, des statistiques et des mathématiques appliquées.
Avant la Seconde Guerre mondiale, tout devait être calculé manuellement, ce qui limitait considérablement les possibilités d’analyse des données. Après la Seconde Guerre mondiale, des ordinateurs et des calculs scientifiques ont été développés. Un seul ordinateur pourrait effectuer tous les comptages et calculs et créer un monde d’opportunités. Depuis cette avancée, il suffit aux utilisateurs de dériver les formules mathématiques, de les écrire dans un algorithme et de charger leurs données.
Avec l’énorme quantité de données disponibles aujourd’hui, un ordinateur ne peut plus gérer seul la charge de travail. Avec la quantité de données que nous devons analyser aujourd’hui, cela devient un problème, et des infrastructures et des bibliothèques spécialisées sont nécessaires pour traiter cette quantité de données. Scikit-learn est la librairie d’apprentissage automatique la plus populaire pour Python. C’est une excellente boîte à outils d’apprentissage automatique. Il existe bien sûr d’autres librairies Python:
- PyBrain pour les réseaux de neurones : Les réseaux de neurones sont des algorithmes d’apprentissage qui imitent le cerveau humain dans l’apprentissage des mécanismes et de la complexité. Les réseaux de neurones sont souvent considérés comme avancés et comme des boîtes noires.
- NLTK ou Natural Language Toolkit : Comme son nom l’indique, son objectif est de travailler avec le langage naturel. C’est une vaste bibliothèque qui est fournie avec plusieurs corpus de texte pour vous aider à modéliser vos propres données.
- Pylearn2 : Une autre boîte à outils d’apprentissage automatique, simailaire à Scikit-learn.
- TensorFlow : une bibliothèque Python de Deep Learning fournie par Google.
Le paysage ne se termine pas avec les libraries Python, bien sûr. Spark est un nouveau moteur d’apprentissage automatique sous licence Apache, spécialisé dans l’apprentissage automatique en temps réel.
Bases de données NoSQL

NoSQL – Not Only SQL
Si vous avez à stocker d’énormes quantités de données, vous avez besoin d’un logiciel spécialisé dans la gestion et l’interrogation de ces données. C’est traditionnellement le terrain de jeu de bases de données relationnelles telles que Oracle SQL, MySQL, etc. Bien qu’ils soient toujours la technologie de référence pour de nombreux cas d’utilisation, de nouveaux types de bases de données ont émergé sous le regroupement des bases de données NoSQL.
Le nom de ce groupe peut être trompeur, car «No» dans ce contexte signifie «Not Only». Le manque de fonctionnalités en SQL n’est pas la principale raison du changement de paradigme, mais les bases de données traditionnelles présentaient des lacunes qui ne leur permettaient pas de s’adapter correctement.
En résolvant plusieurs des problèmes des bases de données traditionnelles, les bases de données NoSQL permettent une croissance pratiquement sans fin des données. Ces lacunes concernent toutes les propriétés Big Data :
- La capacité de stockage ou de traitement ne peut pas s’étendre au-delà d’un seul nœud
- ils n’ont aucun moyen de gérer des formes de données en continu, graphiques ou non structurées.
Outils de planification
Les outils de planification aident à automatiser les tâches répétitives et à déclencher des tâches en fonction d’événements tels que l’ajout d’un nouveau fichier dans un dossier. Celles-ci ressemblent à des outils tels que CRON sous Linux, mais sont spécialement développées pour le Big Data. Vous pouvez par exemple les utiliser pour démarrer une tâche MapReduce lorsqu’un nouvel ensemble de données est disponible dans un répertoire.
Outils d’analyse comparative
Cette classe d’outils a été développée pour optimiser votre installation Big Data en fournissant des suites de profilage standardisées. Une suite de profilage est issue d’un ensemble représentatif de travaux Big Data. L’analyse comparative et l’optimisation de l’infrastructure et de la configuration Big Data ne sont pas souvent des tâches réservées aux Data Scientists, mais à un Data Engineer spécialisé dans la mise en place d’une infrastructure informatique.
L’utilisation d’une infrastructure optimisée peut faire une grande différence de coûts. Par exemple, si vous pouvez gagner 10% sur un cluster de 100 serveurs, vous économisez le coût de 10 serveurs.
Sécurité
Voulez-vous que tout le monde ait accès à toutes vos données? Vous avez probablement besoin d’un contrôle précis de l’accès aux données, mais vous ne voulez pas le gérer application par application. Les outils de sécurité Big Data vous permettent d’avoir un contrôle central et précis de l’accès aux données.
